New Convolutional Neural Networks for Images
Contents
- 1 Understanding Convolutional Neural Networks (CNNs)
- 2 New Convolutional Neural Networks for Images
- 3 Applications of New CNN Models in Image Recognition
- 4 Comparison of Popular CNN Architectures
- 5 How New CNNs Improve Image Classification Accuracy
- 6 Challenges and Future Directions
New convolutional neural networks for images have revolutionized the field of computer vision by significantly improving accuracy, efficiency, and computational performance. As artificial intelligence (AI) continues to evolve, these advanced deep learning models play a crucial role in various industries, including healthcare, autonomous vehicles, security, and manufacturing. By leveraging innovative architectures, new convolutional neural networks for images enhance feature extraction, reduce processing times, and optimize performance for real-world applications.
Over the years, traditional CNN models such as LeNet, AlexNet, and VGGNet have paved the way for modern architectures like ResNet, EfficientNet, and transformer-based networks. These improvements have led to better image recognition, object detection, and segmentation capabilities. Today, new convolutional neural networks for images integrate cutting-edge techniques such as attention mechanisms, depth-wise convolutions, and optimized training algorithms to deliver state-of-the-art results.
In this article, we will explore the fundamentals of convolutional neural networks, examine the latest advancements in CNN architectures, and analyze how these innovations are transforming image processing across multiple domains. Additionally, we will discuss the key challenges associated with CNN implementation and highlight future trends that will shape the next generation of deep learning models.
Understanding Convolutional Neural Networks (CNNs)
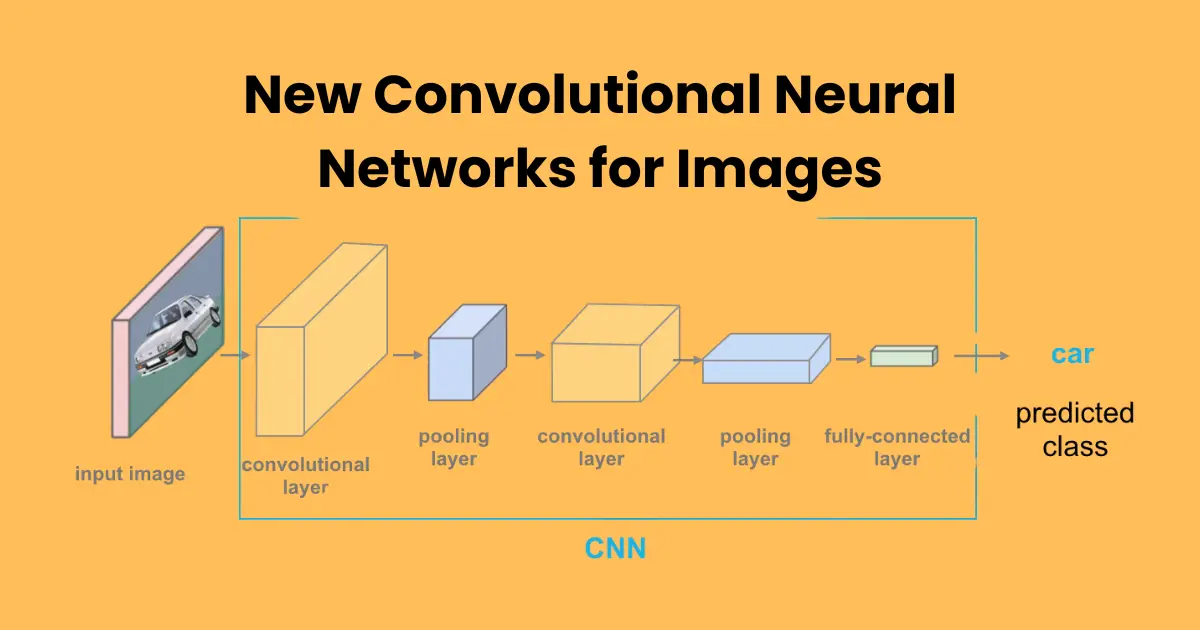
Convolutional Neural Networks (CNNs) are specialized deep learning models designed for processing visual data. Unlike traditional artificial neural networks (ANNs), CNNs efficiently analyze image patterns by preserving spatial relationships between pixels. These networks have transformed computer vision tasks such as image classification, object detection, and facial recognition.

How CNNs Work
CNNs process images through multiple layers, each playing a crucial role in feature extraction and pattern recognition. The network learns to identify key elements such as edges, textures, shapes, and complex objects by passing the image through a series of transformations.
Key Components of CNNs
CNN architectures consist of several essential layers, each serving a unique function:
- Convolutional Layer – This layer applies filters (kernels) to extract features such as edges, corners, and textures from the input image. Convolutions help preserve spatial relationships while reducing computational complexity.
- Pooling Layer – Also known as a subsampling layer, pooling reduces the spatial dimensions of feature maps while retaining essential information. Max pooling and average pooling are common techniques used to downsample images, improving efficiency.
- Activation Function – A non-linear function, such as ReLU (Rectified Linear Unit), is applied to introduce non-linearity into the model, enabling it to learn complex patterns.
- Fully Connected Layer – This layer takes the extracted features and converts them into a final output, typically used for classification tasks.
- Dropout Layer – To prevent overfitting, dropout randomly deactivates a percentage of neurons during training, enhancing the model’s generalization ability.
Evolution of CNN Models
Since their introduction, CNN architectures have undergone significant advancements. Early models such as LeNet-5 laid the foundation for modern deep learning networks. Later, AlexNet demonstrated the power of deep CNNs by achieving breakthrough performance in image classification tasks.
Subsequent models like VGGNet, ResNet, and EfficientNet have introduced improvements in layer design, depth, and computational efficiency. Today, new convolutional neural networks for images incorporate attention mechanisms and transformer-based techniques, further pushing the boundaries of image recognition capabilities.
By continuously refining CNN architectures, researchers have made it possible to achieve higher accuracy, faster processing speeds, and reduced computational costs, making CNNs an integral part of modern AI-driven image analysis.
New Convolutional Neural Networks for Images
Recent advancements in deep learning have led to the development of new convolutional neural networks for images, improving performance in terms of accuracy, efficiency, and scalability. These cutting-edge CNN architectures address limitations of traditional models by integrating novel techniques such as attention mechanisms, depth-wise separable convolutions, and hybrid architectures that combine CNNs with transformers.
Advancements in CNN Architectures
New convolutional neural networks for images have introduced innovative structural modifications that enhance image recognition, segmentation, and object detection. Some of the key improvements include:
- Depth-Wise Separable Convolutions – Used in models like MobileNet, this technique reduces computational complexity by breaking down standard convolutions into depth-wise and point-wise operations. This significantly improves processing speed without compromising accuracy.
- Residual Connections – Introduced in ResNet, residual learning allows deep networks to overcome the vanishing gradient problem. This feature enables CNNs to be trained more effectively, leading to better performance in image classification and object detection.
- Squeeze-and-Excitation Networks (SENets) – These networks improve feature representation by dynamically recalibrating channel-wise feature responses. This technique enhances the ability of CNNs to capture important details in an image.
- Attention Mechanisms – New convolutional neural networks for images incorporate attention-based techniques, such as self-attention and vision transformers (ViTs), which help the model focus on the most important regions of an image.
- Hybrid Architectures – The fusion of CNNs with transformer-based networks has led to powerful models that leverage both local feature extraction (from CNNs) and global feature dependencies (from transformers).
Differences Between Traditional and New CNN Models
| Feature | Traditional CNNs | New CNNs |
| Feature Extraction | Sequential convolution and pooling | Attention-based and hybrid mechanisms |
| Training Efficiency | Requires large datasets and long training times | Optimized training with fewer parameters |
| Computational Cost | High, due to extensive operations | Reduced through depth-wise convolutions and optimizations |
| Scalability | Struggles with very large datasets | More scalable and adaptable |
Performance Improvements in Image Processing
New convolutional neural networks for images significantly enhance various aspects of deep learning-based image processing:
- Higher Accuracy – Improved feature extraction methods increase classification precision.
- Faster Training and Inference – Optimized architectures reduce training time and computational load.
- Better Generalization – Enhanced techniques prevent overfitting, making models more robust in real-world applications.
These innovations are making CNNs more powerful than ever, enabling their use in advanced image processing applications such as autonomous vehicles, medical imaging, and security surveillance. As research progresses, new convolutional neural networks for images will continue to shape the future of AI-driven visual recognition.
Applications of New CNN Models in Image Recognition
New convolutional neural networks for images have significantly enhanced the accuracy and efficiency of image recognition systems. These models are now widely used across various industries, enabling breakthroughs in healthcare, transportation, security, and industrial automation. Below are some of the most impactful applications of new CNN architectures in image recognition.

1. Medical Imaging
CNNs have revolutionized medical diagnostics by enabling automated image analysis for detecting diseases. Advanced CNN architectures are now used in:
- Radiology and X-ray Analysis – Identifying fractures, tumors, and abnormalities in X-rays, CT scans, and MRIs.
- Cancer Detection – Classifying cancerous and non-cancerous tissues in histopathological images.
- Retinal Disease Diagnosis – Detecting diabetic retinopathy and glaucoma in retinal scans.
New convolutional neural networks for images improve diagnostic accuracy and reduce the workload on healthcare professionals, making medical imaging more efficient.
2. Autonomous Vehicles
Self-driving cars rely on CNNs for real-time image recognition and scene understanding. Some key applications include:
- Object Detection – Identifying pedestrians, traffic signs, and other vehicles.
- Lane Detection – Recognizing road boundaries and lane markings.
- Obstacle Avoidance – Detecting obstacles and making split-second driving decisions.
By using CNN-based models, autonomous vehicles can process complex visual environments with greater precision, improving safety and reliability.
3. Security and Surveillance
CNN-powered facial recognition and surveillance systems are transforming security applications. These technologies are widely used for:
- Facial Recognition – Identifying individuals for access control and identity verification.
- Anomaly Detection – Detecting suspicious activities in crowded areas.
- License Plate Recognition – Automating vehicle identification in traffic monitoring systems.
With the introduction of new convolutional neural networks for images, security and surveillance systems have become more robust, reducing false positives and improving real-time performance.
4. Industrial Quality Control
Manufacturing industries leverage CNN-based image recognition for automated inspection and defect detection. Some notable applications include:
- Product Quality Inspection – Identifying defects in production lines.
- Automated Sorting Systems – Classifying objects based on size, shape, or color.
- Predictive Maintenance – Detecting early signs of wear and tear in machinery.
New CNN models enhance the precision and efficiency of industrial quality control, reducing human error and operational costs.
5. Retail and E-Commerce
CNNs are transforming the retail sector by enabling AI-driven image recognition in:
- Visual Search – Allowing customers to find products by uploading images.
- Automated Checkout – Using object recognition to enable cashier-less stores.
- Customer Behavior Analysis – Tracking customer movements to optimize store layouts.
6. Agriculture and Environmental Monitoring
AI-driven CNN models are improving agricultural productivity by automating crop monitoring and pest detection. Applications include:
- Crop Disease Detection – Identifying plant diseases from leaf images.
- Soil Quality Assessment – Analyzing soil textures and moisture levels.
- Wildlife Conservation – Monitoring endangered species through satellite imagery.
Comparison of Popular CNN Architectures
New convolutional neural networks for images have evolved significantly, leading to various architectures optimized for different applications. Each model introduces unique innovations to improve accuracy, efficiency, and scalability. Below is a comparison of the most widely used CNN architectures.
1. ResNet vs. EfficientNet
| Feature | ResNet | EfficientNet |
| Architecture | Uses residual connections to enable deeper networks | Uses compound scaling to optimize model size and efficiency |
| Depth | Can be extremely deep (e.g., ResNet-152) | Optimized depth, width, and resolution scaling |
| Training Speed | Slower due to deeper layers | Faster and more computationally efficient |
| Use Cases | Image classification, object detection | Edge devices, mobile applications, real-time processing |
Key Takeaway: ResNet is excellent for handling complex datasets, while EfficientNet is optimized for speed and efficiency, making it ideal for real-time applications.
2. Vision Transformers (ViTs) vs. CNNs
| Feature | Vision Transformers (ViTs) | Traditional CNNs |
| Architecture | Uses self-attention mechanisms to process images | Uses convolutional layers for local feature extraction |
| Computational Efficiency | Requires large datasets and more computing power | More efficient for small to mid-size datasets |
| Generalization | Better at capturing long-range dependencies | Performs well on local feature extraction |
| Use Cases | Large-scale vision tasks, medical imaging, NLP applications | Standard image classification, object detection |
Key Takeaway: Vision Transformers outperform CNNs on large-scale datasets but require significantly more training data and computational power.
3. MobileNet vs. ShuffleNet (Lightweight CNNs for Mobile Applications)
| Feature | MobileNet | ShuffleNet |
| Efficiency | Uses depth-wise separable convolutions | Uses point-wise group convolutions for efficiency |
| Model Size | Small and optimized for mobile devices | Extremely lightweight with lower computational cost |
| Performance | Balanced accuracy and speed | Higher speed but slightly lower accuracy |
| Use Cases | Mobile applications, real-time object detection | Embedded systems, IoT devices |
Key Takeaway: Both MobileNet and ShuffleNet are ideal for mobile and edge devices, with ShuffleNet offering better speed and MobileNet balancing speed with accuracy.
New convolutional neural networks for images offer a wide range of solutions depending on the application. ResNet is suited for deep learning tasks, EfficientNet provides optimized performance, Vision Transformers excel in large datasets, and MobileNet/ShuffleNet are best for lightweight applications. The choice of CNN architecture depends on factors such as computational resources, dataset size, and real-time processing requirements.
How New CNNs Improve Image Classification Accuracy
New convolutional neural networks for images have introduced several advancements that significantly enhance image classification accuracy. These improvements result from architectural innovations, optimized training techniques, and enhanced feature extraction methods. Below are the key factors that contribute to improved classification performance.

1. Deeper and More Efficient Architectures
Traditional CNNs faced challenges with vanishing gradients when increasing depth. Modern architectures solve this by incorporating:
- Residual Connections (ResNet) – Skip connections help retain important information across layers, preventing gradient loss.
- Dense Connections (DenseNet) – Feature maps from previous layers are reused, improving information flow and reducing redundancy.
- Efficient Scaling (EfficientNet) – Simultaneously optimizes depth, width, and resolution to enhance accuracy with fewer parameters.
2. Improved Feature Extraction Techniques
New convolutional neural networks for images use advanced convolution operations to extract richer feature representations:
- Depth-Wise Separable Convolutions (MobileNet, Xception) – Reduce computational complexity while maintaining accuracy.
- Dilated Convolutions (DeepLab) – Expand the receptive field without increasing computation, improving segmentation accuracy.
- Attention Mechanisms (SENet, Transformers) – Focus on the most relevant parts of an image, filtering out noise and enhancing classification performance.
3. Optimization Techniques for Better Generalization
Modern CNNs use various optimizations to prevent overfitting and improve generalization:
- Dropout and Batch Normalization – Reduce overfitting by preventing co-adaptation of neurons and stabilizing learning.
- Data Augmentation (AutoAugment, RandAugment) – Enhances model robustness by artificially increasing dataset diversity.
- Self-Supervised Learning (SimCLR, MoCo) – Enables models to learn from unlabeled data, improving feature learning.
4. Hybrid CNN-Transformer Models
The combination of CNNs with transformer-based models has revolutionized image classification. Hybrid models like Vision Transformers (ViTs) and Convolutional Vision Transformers (CCTs) leverage both local and global dependencies, leading to:
- Better object localization and recognition.
- Stronger adaptability to complex images.
- Higher accuracy on large-scale datasets.
5. Faster and More Efficient Training Techniques
New CNN architectures incorporate training improvements such as:
- Knowledge Distillation – Smaller networks learn from larger models to improve accuracy with fewer parameters.
- Gradient Clipping and Adaptive Optimizers – Techniques like AdamW enhance stability and speed up convergence.
- Federated Learning – Enables distributed training without data sharing, improving model performance across different environments.
Challenges and Future Directions
New convolutional neural networks for images have greatly improved image classification, object detection, and segmentation. However, despite these advancements, several challenges remain. Overcoming these limitations will define the future direction of CNN research and applications.

Challenges in CNNs
1. High Computational Cost
- Modern CNN architectures require significant processing power and large-scale GPUs for training.
- Inference on edge devices (smartphones, IoT devices) remains a challenge due to high resource requirements.
- Solutions: Model compression techniques like pruning, quantization, and knowledge distillation help reduce computational overhead.
2. Large Training Data Requirements
- CNNs typically need massive labeled datasets for high accuracy.
- In scenarios with limited data, performance may degrade due to overfitting.
- Solutions: Self-supervised learning and few-shot learning reduce reliance on labeled data.
3. Vulnerability to Adversarial Attacks
- CNNs are sensitive to small perturbations in input images, leading to misclassification.
- Security risks arise in applications like autonomous driving and biometric authentication.
- Solutions: Adversarial training and robust feature extraction methods can enhance security.
4. Lack of Explainability and Interpretability
- CNNs operate as black-box models, making it difficult to understand decision-making processes.
- This is a concern in critical applications like healthcare and finance.
- Solutions: Explainable AI (XAI) techniques, such as attention maps and saliency methods, improve transparency.
5. Generalization Issues
- CNNs trained on specific datasets may struggle with unseen data due to domain shifts.
- Solutions: Domain adaptation and transfer learning help CNNs generalize better to new environments.
Future Directions of CNNs
1. Integration of CNNs with Transformers
- Hybrid models combining CNNs with Vision Transformers (ViTs) improve both local and global feature extraction.
- Expect CNN-transformer hybrids to dominate future image recognition tasks.
2. Efficient CNN Models for Edge AI
- Developing lightweight CNNs for real-time processing on mobile devices and IoT will be crucial.
- Models like MobileNetV3, ShuffleNet, and TinyML architectures will continue evolving.
3. Self-Supervised and Few-Shot Learning
- Reducing dependence on large labeled datasets will be a key research focus.
- Self-supervised learning (SSL) methods, like SimCLR and MoCo, will enhance unsupervised learning capabilities.
4. 3D CNNs and Multimodal Learning
- Future CNNs will move beyond 2D image recognition to handle 3D medical imaging, LiDAR data, and multimodal inputs (e.g., combining image and text data).
5. More Robust and Secure CNNs
- Strengthening CNNs against adversarial attacks and bias issues will make AI systems more reliable.
- Research into defensive distillation and robust training methods will grow.
New convolutional neural networks for images continue to push the boundaries of AI-driven image analysis. While challenges like computational cost, security risks, and data dependence persist, ongoing research into hybrid architectures, self-supervised learning, and efficient CNN models will define the future of deep learning in computer vision. As technology advances, CNNs will become more powerful, interpretable, and adaptable, unlocking new possibilities in AI-driven image recognition.
Conclusion
New convolutional neural networks for images have revolutionized the field of computer vision, enabling more accurate and efficient image classification, object detection, and segmentation. Through architectural innovations such as residual connections, attention mechanisms, and depth-wise separable convolutions, modern CNNs have overcome many limitations of traditional models. These advancements have led to higher accuracy, faster training times, and improved scalability, making CNNs more effective in real-world applications.
Despite their success, challenges remain, including high computational costs, large data requirements, vulnerability to adversarial attacks, and interpretability issues. However, ongoing research in self-supervised learning, hybrid CNN-transformer models, and efficient CNN architectures for edge devices is addressing these concerns. The future of CNNs lies in making them more robust, adaptable, and interpretable, ensuring their continued impact in fields like healthcare, autonomous vehicles, security, and industrial automation.
As deep learning technology advances, new convolutional neural networks for images will continue to shape the next generation of AI-driven visual recognition systems, unlocking more powerful, intelligent, and scalable solutions for diverse industries.